EvaluationLogger provides a flexible, incremental way to log evaluation data directly from your Python or TypeScript code. You don’t need deep knowledge of Weave’s internal data types; simply instantiate a logger and use its methods (log_prediction, log_score, log_summary) to record evaluation steps.
This approach is particularly helpful in complex workflows where the entire dataset or all scorers might not be defined upfront.
In contrast to the standard Evaluation object, which requires a predefined Dataset and list of Scorer objects, the EvaluationLogger allows you to log individual predictions and their associated scores incrementally as they become available.
Prefer a more structured evaluation?If you prefer a more opinionated evaluation framework with predefined datasets and scorers, see Weave’s standard Evaluation framework.The
EvaluationLogger offers flexibility while the standard framework offers structure and guidance.Basic workflow
- Initialize the logger: Create an instance of
EvaluationLogger, optionally providing metadata about themodelanddataset. Defaults will be used if omitted. :::important Track token usage and cost To capture token usage and cost for LLM calls (e.g. OpenAI), initializeEvaluationLoggerbefore any LLM invocations**. If you call your LLM first and then log predictions afterward, token and cost data are not captured. ::: - Log predictions: Call
log_predictionfor each input/output pair from your system. - Log scores: Use the returned
ScoreLoggertolog_scorefor the prediction. Multiple scores per prediction are supported. - Finish prediction: Always call
finish()after logging scores for a prediction to finalize it. - Log summary: After all predictions are processed, call
log_summaryto aggregate scores and add optional custom metrics.
After calling
finish() on a prediction, no more scores can be logged for it.Basic example
The following example shows how to useEvaluationLogger to log predictions and scores inline with your existing code.
- Python
- TypeScript
The
user_model model function is defined and applied to a list of inputs. For each example:- The input and output are logged using
log_prediction. - A simple correctness score (
correctness_score) is logged vialog_score. finish()finalizes logging for that prediction. Finally,log_summaryrecords any aggregate metrics and triggers automatic score summarization in Weave.
Advanced usage
Get outputs before logging
You can first compute your model outputs, then separately log predictions and scores. This allows for better separation of evaluation and logging logic.- Python
- TypeScript
Log rich media
Inputs, outputs, and scores can include rich media such as images, videos, audio, or structured tables. Simply pass a dict or media object into thelog_prediction or log_score methods.
- Python
Log and compare multiple evaluations
WithEvaluationLogger, you can log and compare multiple evaluations.
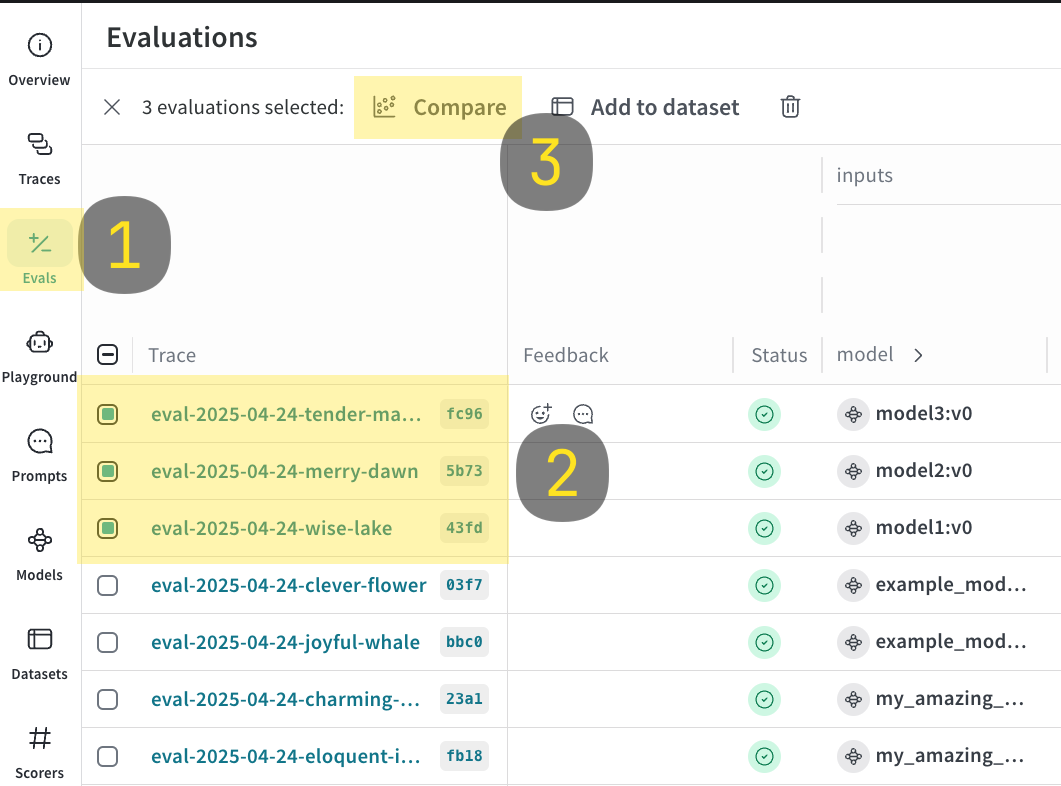
- Run the code sample shown below.
-
In the Weave UI, navigate to the
Evalstab. - Select the evals that you want to compare.
-
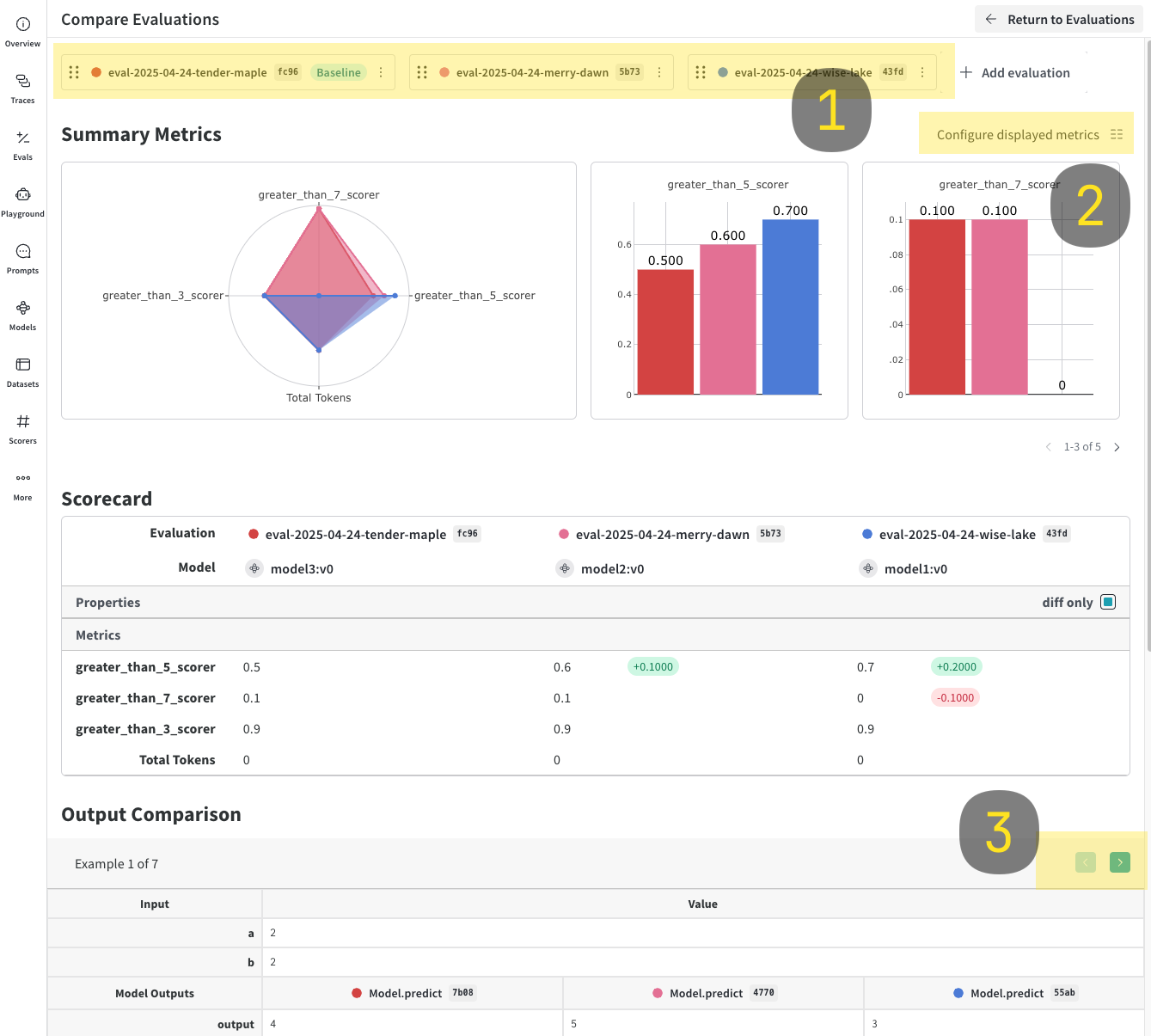
Click the Compare button. In the Compare view, you can:
- Choose which Evals to add or remove
- Choose which metrics to show or hide
- Page through specific examples to see how different models performed for the same input on a given dataset
- Python
- TypeScript
Usage tips
- Python
- TypeScript
- Call
finish()promptly after each prediction. - Use
log_summaryto capture metrics not tied to single predictions (e.g., overall latency). - Rich media logging is great for qualitative analysis.